What is Machine Learning
Field of study that gives computers the ability to learn without being explicitly programmed. (Arthur Samuel 1959)
Machine Learning is like having a super smart friend who learns from examples. You give it data (like pictures of cats and dogs) and tell it what each one is. The machine looks for patterns and learns from this data. Later, when you show it a new picture, it can make a pretty good guess whether it’s a cat or a dog, even though it hasn’t seen that exact picture before.
The more opportunities you give a learning algorithm to learn the better it will perform.
Learning Algorithm
Learning algorithm is like getting some sets of tools, so we need have great tools and make sure we know how to use it.
- Pick up the right one which can solve the problem effectively.
- Make sure the right implementation of it.
Supervise Learning
Supervise Learning is like you train a computer with a bunch of examples that already have the answers (or labels). You give the computer data (like pictures of fruits) along with the correct labels (like "apple" or "orange"). The computer learns from these examples and, starts to recognize patterns. Later, when you show the computer a new picture of a fruit, it can make an educated guess.
Regression
To predict a number from infinitely many possible outputs.
e.g. To predict the price of housing in the future this is an example of supervised learning, because a dataset, the right answer that is the label or the right price on the plots, was provided to algorithm
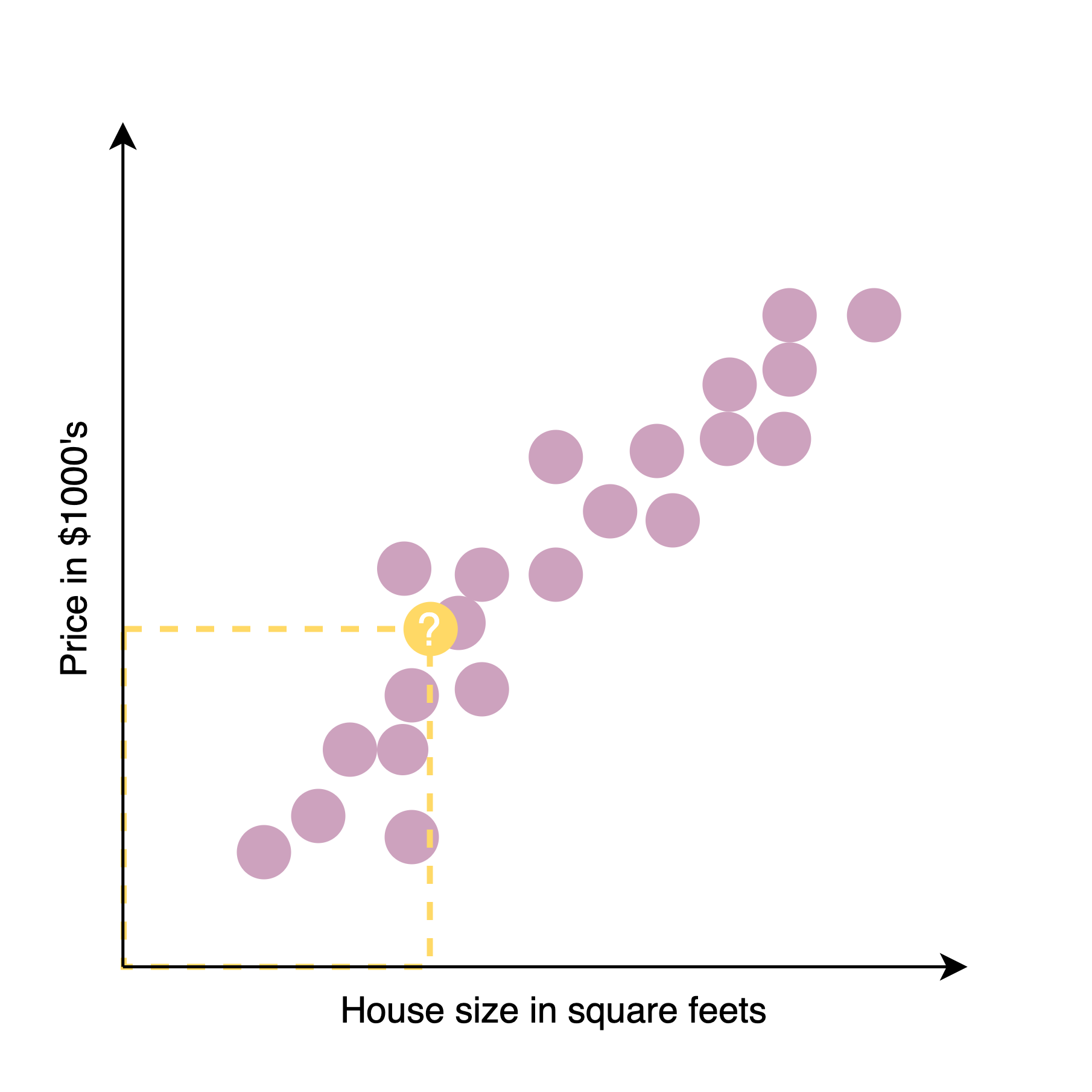
With those data, someone wants to know what's the price for a 750 square feet house. Then the algorithm will choose the most appropriate line or curve or other thing to fit to this data.
Simply, learning inputs & outputs or x to y mappings to generate a regression to predict.
Classification
There's another kind of supervised learning algorithm called classification.
Example: Breast cancer detection, like defining or judge a lump is malignant (dangerous) or benign (not dangerous).
There will be a huge dataset about tumors of various sizes. And those tumors in dataset were labelled as malignant (designated with 1) or benign (designated with 0).
| Size | Diagnosis |
|---|---|
| 1 | 0 |
| 2 | 1 |
| 2.5 | 0 |
| 4 | 0 |
| 5 | 1 |
| 7 | 0 |
| 7.25 | 1 |
| 8 | 1 |
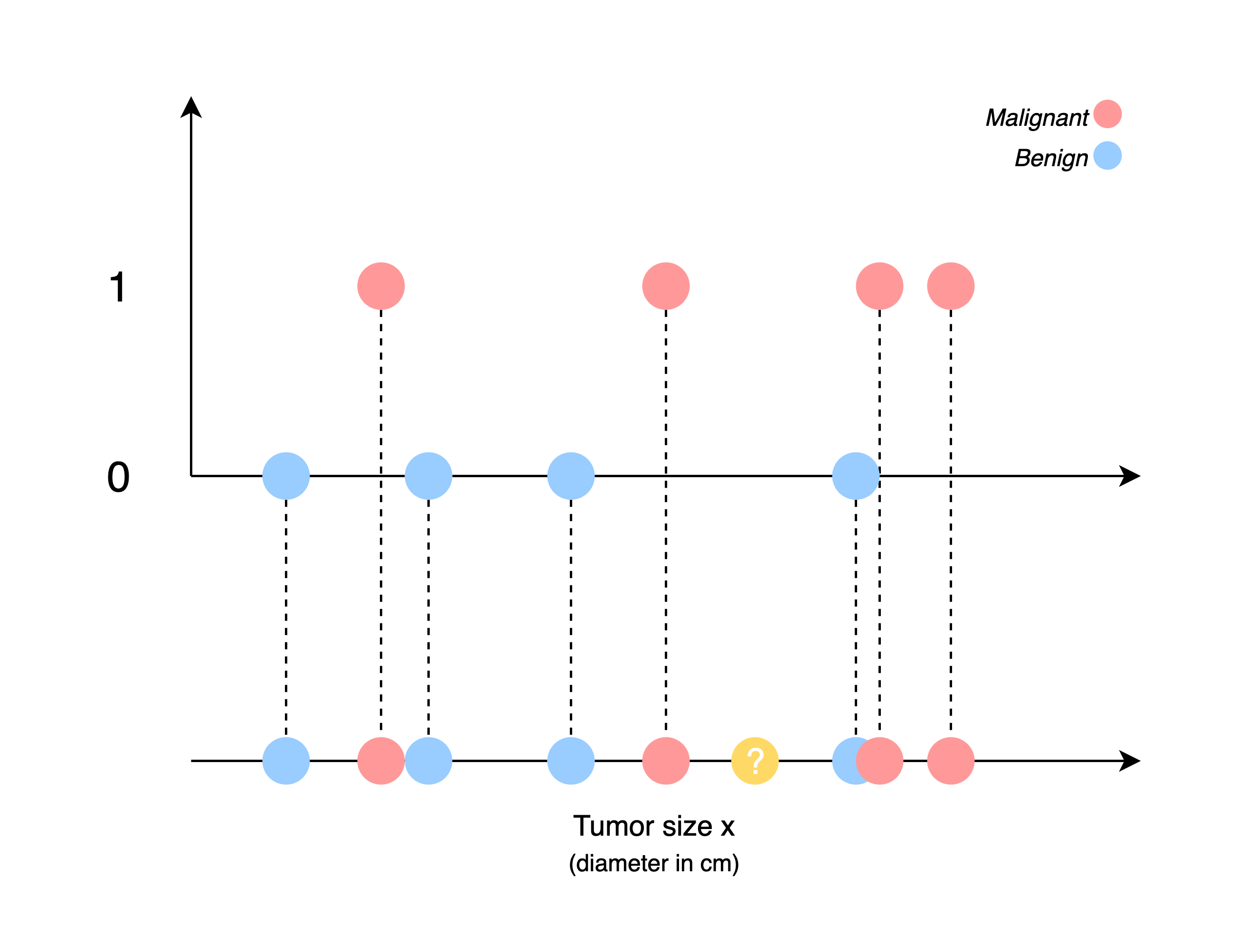
If there's a tumor with known size the system will classify the tumor as benign or malignent with input size.
However, the input varibles can be more than 1.
Here's an example, instead of just knowing the size of tumors, the age is known as well. So there are 2 inputs: Tumor Size and Patient Age
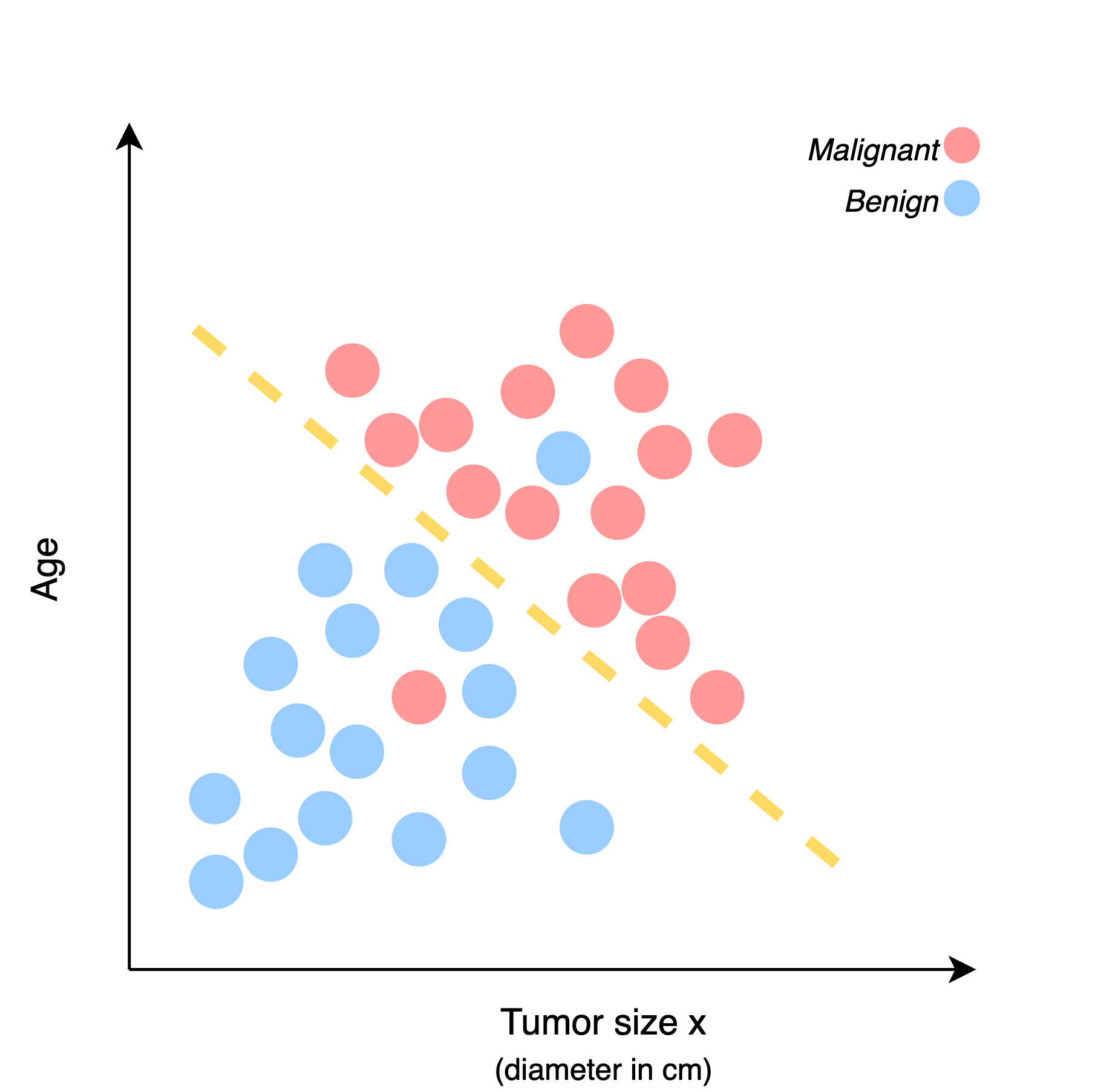
In this case, the algorithm should find the proper boundary line through these data.
Summary
| Feature | Regression | Classification |
|---|---|---|
| Definition | Guessing what | Sorting stuff into categories |
| Output | Continuous, like a non-stop rollercoaster | Categorical/Discrete, like putting people into Hogwarts houses |
| Example Algorithms | - Linear Regression - Polynomial Regression - Ridge Regression - etc., more algorithms to make you cry | - Logistic Regression - Decision Trees - Random Forest - etc., more algorithms to make you cry |
| Example Applications | - Predicting the cost of that fancy castle - Estimating how many cookies you'll eat - Forecasting stock prices | - Email spam detection like "keep" and "burn" piles - Image classification like naming everything they see - Disease diagnosis |
| Decision Boundary | No way | Separates different classes |
| Real-world Example | Predicting temperatures based on historical data | Classifying emails as spam or non-spam |
It seems like that classification might need regression to implement?
Classification algorithms sometimes use techniques that resemble regression to predict probabilities or scores that are then used to make discrete class decisions. This overlap can make it seem like classification depends on regression. However, their objectives and outputs are fundamentally different: regression predicts continuous values, while classification predicts discrete labels.
Unsupervise Learning
What different from supervised learning is that dataset provided for unsupervised learning are not labeled.
Imagine you're at a party with a bunch of people you've never met. You want to figure out who might be friends or who has similar interests, but no one tells you anything directly. So, you start observing and listening to conversations. You notice some people talking a lot about sports, others about movies, and some about cooking. Based on these patterns, you group people into clusters, like "sports fans," "movie buffs," and "foodies."
| Supervise Learning | Unsupervise Learning |
|---|---|
| Learn from data labeled with the "right answers" | find something interesting in unlabeled data |
Clustering Learning (Group similar data)
If the previous example of tumor is reused at here, the data on patients' tumor size and age are given but not whether the tumor was benign or malignant. There is no red or blue color because the labels indicating whether a tumor is benign or malignant were not provided.
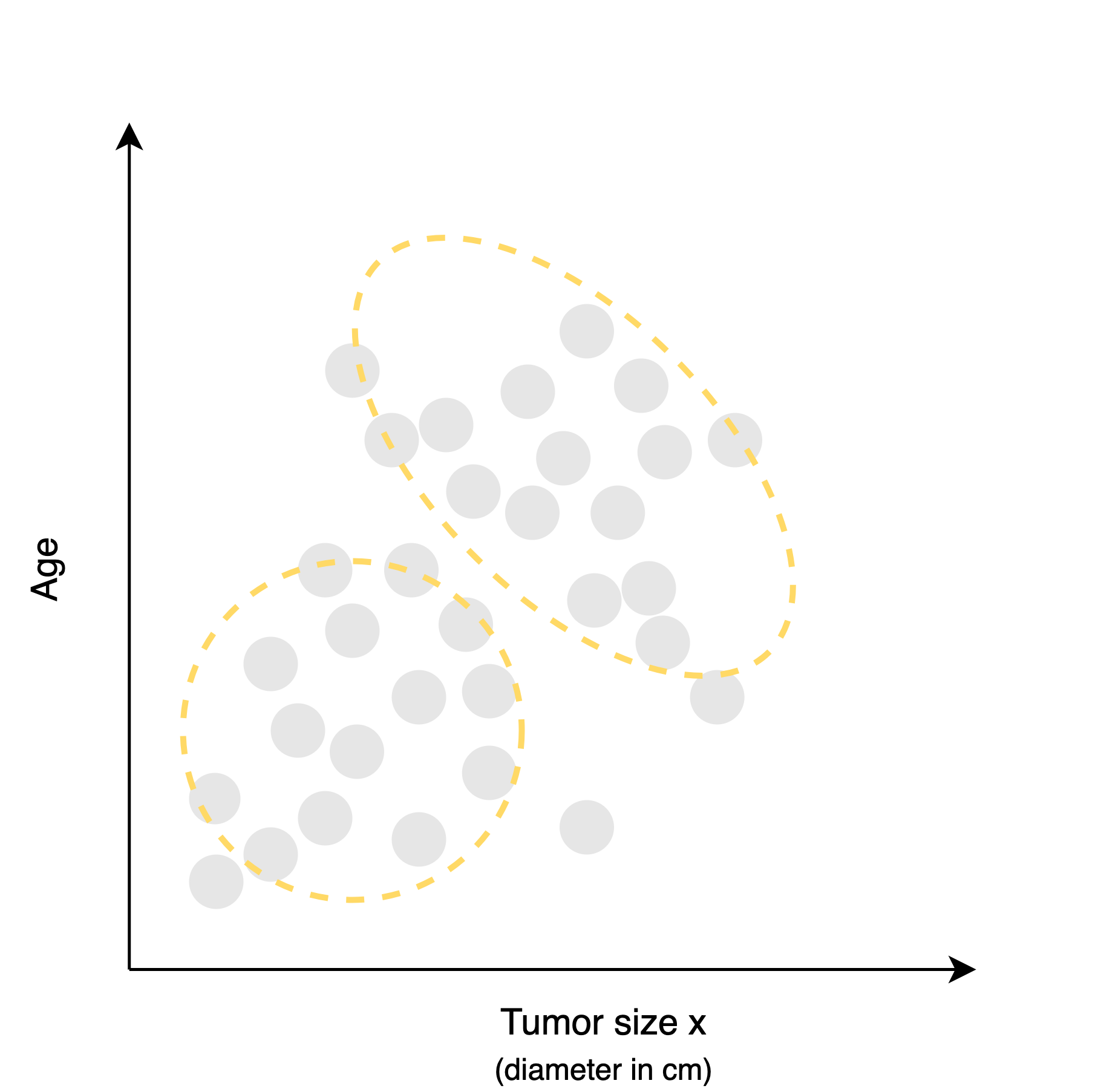
It is not supposed to diagnose, instead, the task is to find some structure or pattern that might be in this data. From the given dataset it might decide, that there are 2 clusters or groups in different position. And this is a particular type of unsupervised learning called clustering.
Anomaly Detection (Find unusual data points)
Imagine you're a baker making vanilla cupcakes every day. One day, you find a green cupcake with sprinkles among your usual batch. It stands out because it's not what you expect.
Anomaly detection is like noticing that odd cupcake. It helps you spot things that don't fit in with the usual pattern, whether it's in cupcakes or data. So, it's like saying, "Hey, this one looks different!"
Dimensionality Reduction (Compress data using fewer numbers)
Dimensionality Reduction in data is like packing for that trip. You start with a big "suitcase" full of all the data features (like height, weight, color, etc.). But not all of them are useful for what you're trying to do. So, you sort through and pick only the most important features, the ones that really matter for your task, and leave the rest behind.
This way, just like traveling with a lighter suitcase, your data becomes easier to handle, process, and understand. And best of all, you can still enjoy the trip (or get good results) without all the extra baggage!
Summary
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Definition | Learning from labeled data (given "right answers") | Learning from unlabeled data |
| Input | Input data with corresponding output labels | Input data without explicit output labels |
| Goal | Predict outcomes based on input data | Discover hidden patterns or intrinsic structures |
| Algorithms | - Linear Regression - Logistic Regression - Decision Trees - Random Forests - Support Vector Machines (SVM) - Neural Networks | - Clustering (e.g., K-means, Hierarchical Clustering) - Association (e.g., Apriori, Eclat) - Dimensionality Reduction (e.g., PCA, t-SNE) |
| Example Applications | - Spam Detection - Sentiment Analysis - Image Classification - Medical Diagnosis | - Customer Segmentation - Anomaly Detection - Market Basket Analysis - Data Visualization |
| Training Process | Learns a function that maps input to output | Identifies hidden patterns in data |
| Evaluation | Performance measured with metrics like accuracy, precision, recall, F1-score, etc. | Evaluation is less straightforward, often relies on the interpretation of discovered patterns |
| Data Requirement | Requires a large amount of labeled data | Can work with unlabeled data |